INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
練習
INSERT INTO employees (employeeID, employeeName, age, salary, supervisor, departmentID)
VALUES(100, "Josh Donaldson", 35, 3500, null, 1);
SELECT * FROM employees; -> 查詢指令
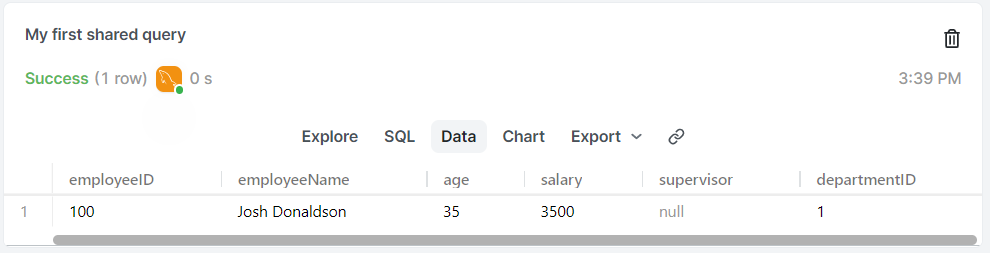
需要確保值的順序與表中 column 的順序相同
INSERT INTO table_name
VALUES (value1, value2, value3, ...);
練習
INSERT INTO employees
VALUES(101, "Mike Napoli", 40, 2400, 100, 1);
SELECT * FROM employees; -> 查詢指令
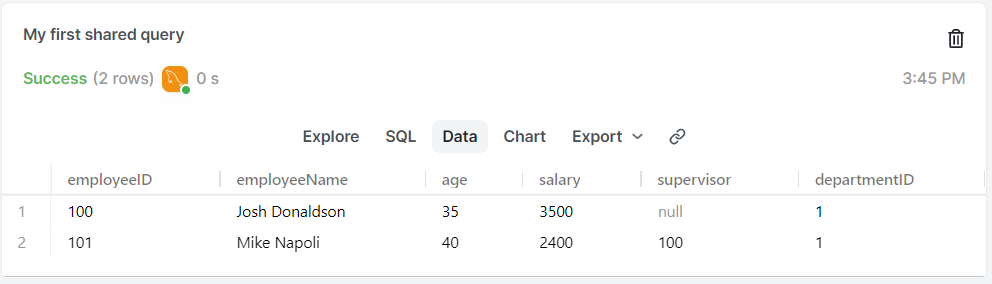
假設沒有加 employeeID,結果還會出現 employeeID 是 102,是因為設定 employeeID 時有寫AUTO_INCREMENT
INSERT INTO employees (employeeName, age, salary, supervisor, departmentID)
VALUES("Cody Allen", 37, 2400, 100, 2);
SELECT * FROM employees; -> 查詢指令
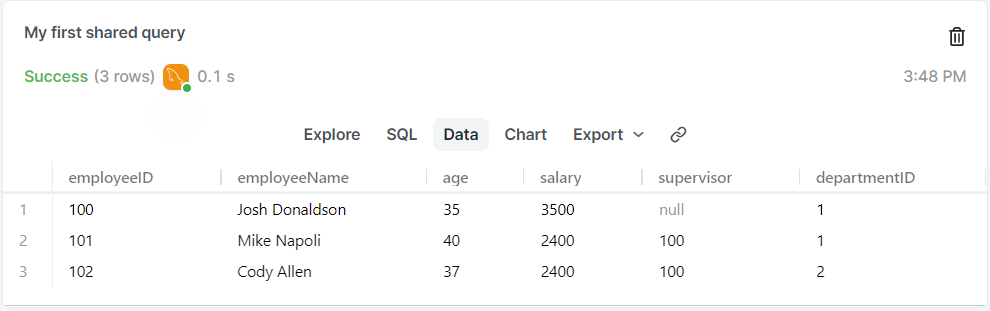
修改表格中的現有記錄
注意!! WHERE 可以指定應該更新哪些記錄,如果省略 WHERE,表中的所有記錄都將被更新
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition; -> 說明要更改表格中的哪些紀錄的位置
練習
輸入資料時不小心放錯值,108, "Oliver Perez", 30, 1500, 102, 2,如何將 108 改成 107
UPDATE employees
SET employeeID = 107
WHERE employeeID = 108;
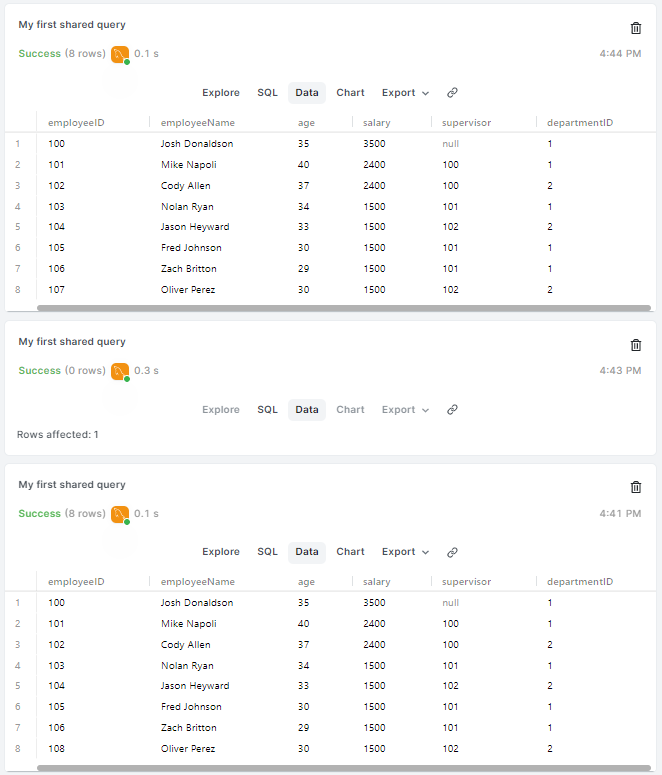
省略 WHERE,表中的所有記錄都將被刪除
DELETE 語法只能夠刪除表格中的資料,但表格本身依然存在
DELETE FROM table_name WHERE condition;
練習
DELETE FROM employees WHERE employeeID = 107;
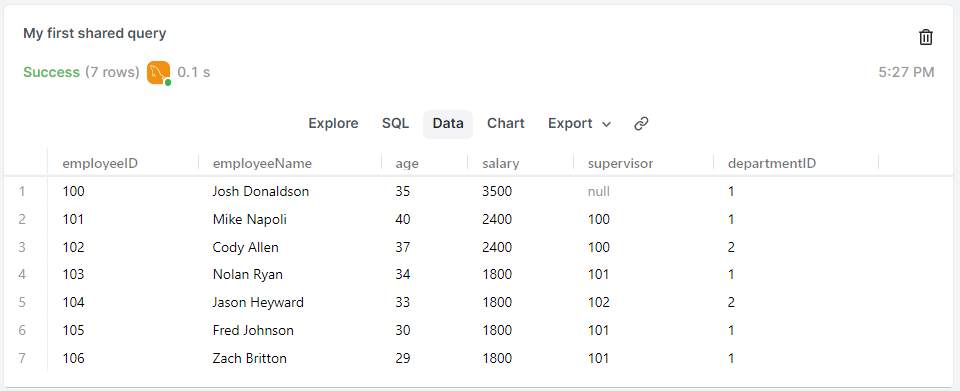
DROP TABLE table_name;
SELECT column1, column2, ...
FROM table_name;
練習
SELECT employeeID, employeeName, age
FROM employees;
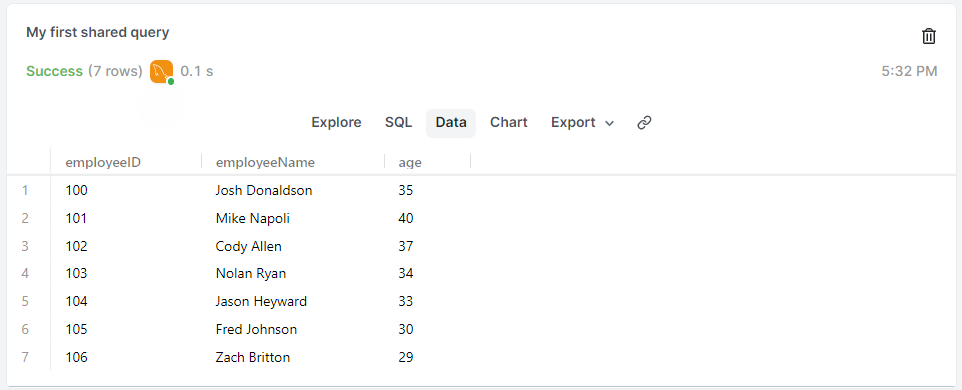
SELECT * FROM table_name;
ORDER BY 關鍵字用於對查詢結果按升序或降序進行排序 (默認是升序)
ASC -> 升序,DESC -> 降序
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 (ASC|DESC), column2 (ASC|DESC), …;
練習
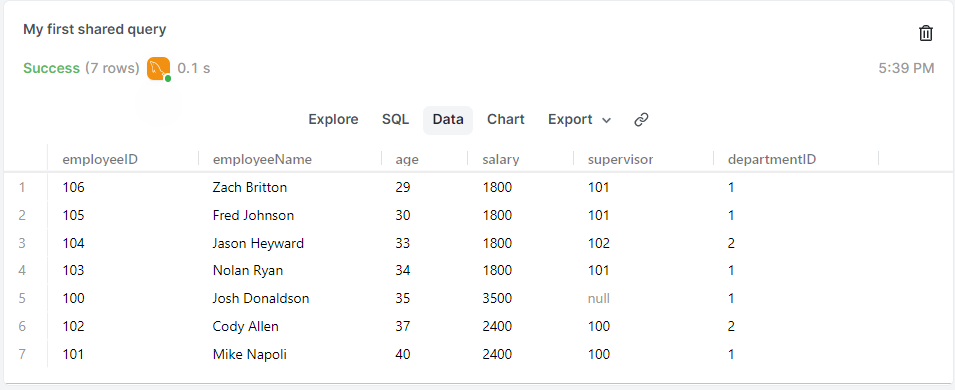
SELECT *
FROM employees
ORDER BY age;
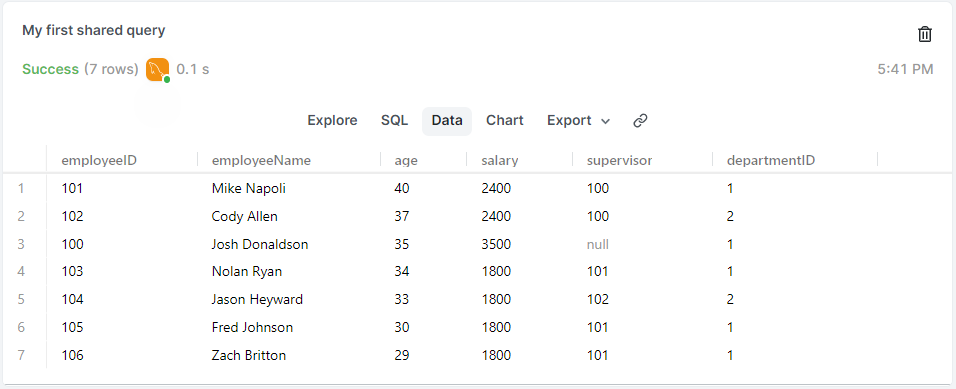
由大到小
SELECT *
FROM employees
ORDER BY age DESC;
使用WHERE,可以使用運算符:=, <, <=, >, >=, 不等於<>, IN, BETWEEN, != 等等
SELECT column1, column2, ...
FROM table_name
WHERE condition;
練習
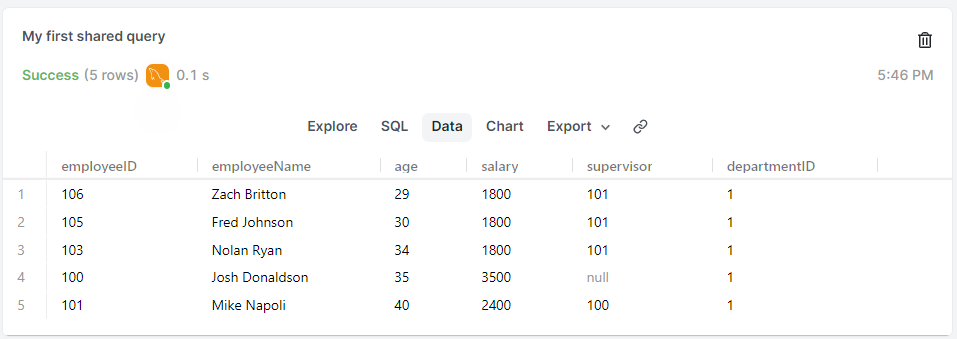
SELECT *
FROM employees
WHERE departmentID = 1
ORDER BY age;
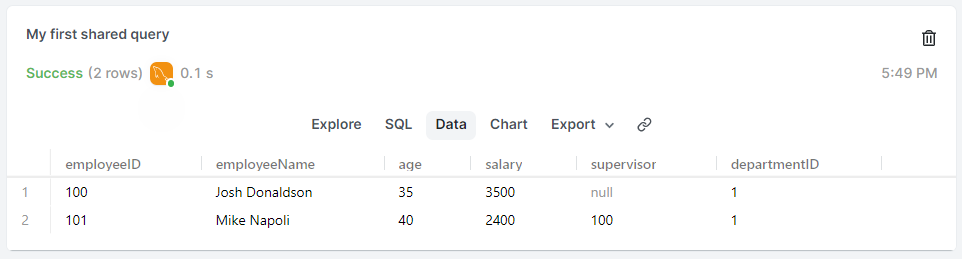
SELECT *
FROM employees
WHERE departmentID = 1 AND salary >= 2000
ORDER BY age;
JOIN 用於根據兩個或多個表之間的相關 column 的組合
在 JOIN 兩個資料表時,如果不寫JOIN ON,而是只寫JOIN,則合併的結果為兩個資料表間的笛卡兒乘積 ,也就是兩個資料表中所有的可能組合
SELECT column1, column2, ...
FROM table1
JOIN table2 ON table1.columnName = table2.columnName;
練習
SELECT *
FROM department d
JOIN employees e (後面_e是簡稱)
ON d.headID = e.employeeID;

SQL
優點:
由於關係型資料庫改變表格架構較為困難,通常會保持數據的一致性
資料庫內的資料表連結性高,可以進行 Join 等複雜查詢
產品成熟度高、穩定性也高,經過多年發展,較少 bug 需要處理,且提供報表生成等商業功能
缺點:
擴展困難。SQL 通常會垂直擴展 (增加昂貴和重量級的伺服器),單台伺服器要持有整個資料庫來確保可靠性與數據的持續可用性。這樣做的代價就是非常昂貴、擴展受到限制
成本高:企業級資料庫的 License 價格很驚人,並且隨著系統的規模,而不斷上升
讀寫慢:這種情況主要發生在數據量達到一定規模時,由於 SQL 的系統邏輯非常複雜(MySQL uses both B-Tree, B+Tree, and HASH indexes ),且有可能死鎖 Deadlock 的併發問題,所以其讀寫速度下滑非常嚴重
NoSQL
優點:
可擴展性:NoSQL 資料庫一般的設計都能透過硬體的分散式叢集來向外擴展,雲端伺服器供應商通常將這些操作處理成全受管服務
快速的讀寫:主要例子有 Redis (Remote Dictionary Server),只在 RAM 操作,使得其性能非常出色,每秒可以處理超過 10 萬次讀寫操作。Redis 資料庫的操作,在所有資料都在 RAM 的前提之下,增刪查改都是 O(1)的時間複雜度,不受資料數量影響
低廉的成本:這是 NoSQL 資料庫共有的特點,因為主要都是開源軟體,沒有昂貴的 License 成本
缺點:
不提供對 SQL 的支持:因為不支持 SQL 這樣的傳統資料庫,將會對用戶產生一定的學習和應用遷移成本
支持的特性不夠豐富:現有產品所提供的功能都比較有限,也不像 MS SQL Server 和 Oracle 那樣能提供各種附加功能,比如自動生成報表等
現有產品的不夠成熟:大多數產品都還處於初創期
下一篇文章是總結。


 iThome鐵人賽
iThome鐵人賽